Editor Features¶
smelt's Language Server Protocol (LSP) implementation brings the kind of editor experience you'd expect from a statically-typed language to your data pipeline. Every feature works in real time as you type -- no build step, no waiting.
Setup first
If you haven't configured the LSP yet, see Editor Setup to get started.
Real-Time Diagnostics¶
Catch errors the moment you make them, not minutes later when a pipeline run fails.
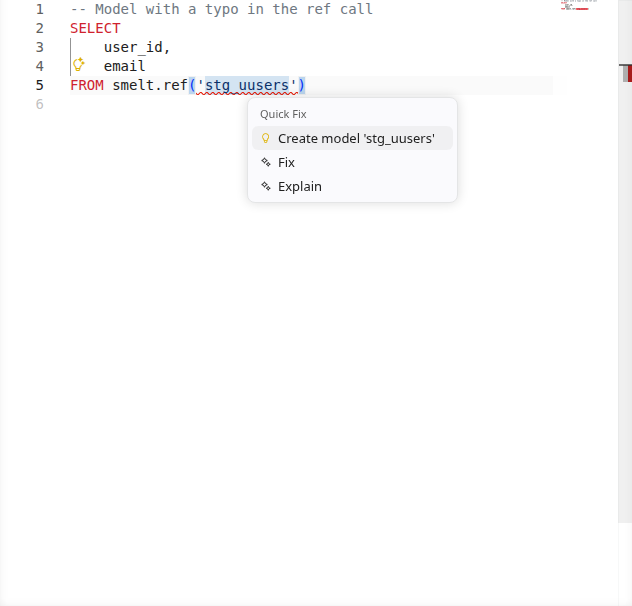
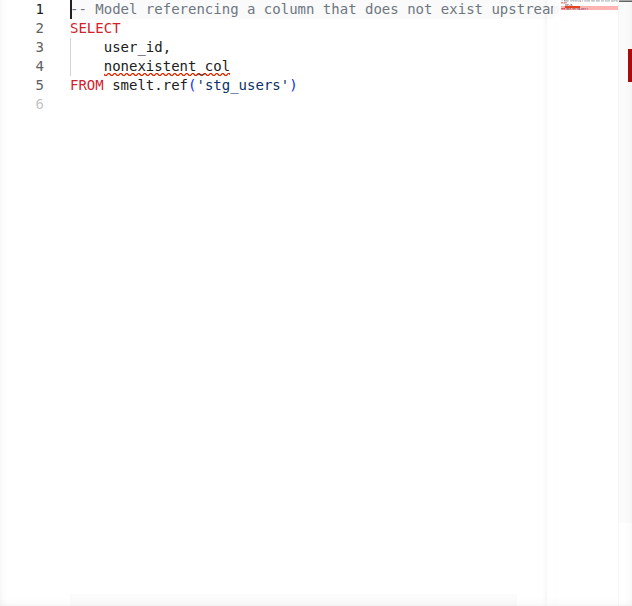
smelt validates your SQL continuously: undefined model references, undeclared columns, type mismatches, and parse errors all surface as you type. In dbt, a typo in a ref() call means a failed build. In smelt, it's a red squiggle before you finish the line.

The diagnostics cover the full range of common errors:
- Undefined refs -- referencing a model that doesn't exist
- Undeclared columns -- using a column name not present in the upstream schema or source
.yml - Parse errors -- SQL syntax mistakes
- Type mismatches -- operations on incompatible types
Go-to-Definition¶
Trace your data lineage by jumping directly to definitions -- from a smelt.<name> call to the upstream model, from a column reference to where it's defined, or from a CTE usage to its definition.
In a large pipeline with dozens of models, you can follow the data flow without ever leaving your editor. No more grepping for model names or manually opening files.

Go-to-definition works for:
| Cursor position | Jumps to |
|---|---|
smelt.model_name |
The referenced model's SQL file |
smelt.sources.schema.table |
The per-entity source .yml file |
| CTE name in FROM/JOIN | The CTE definition in the WITH clause |
Table alias (e.g., t in t.column) |
Where the alias is defined |
| Column reference | The column's definition in the upstream SELECT or source .yml |

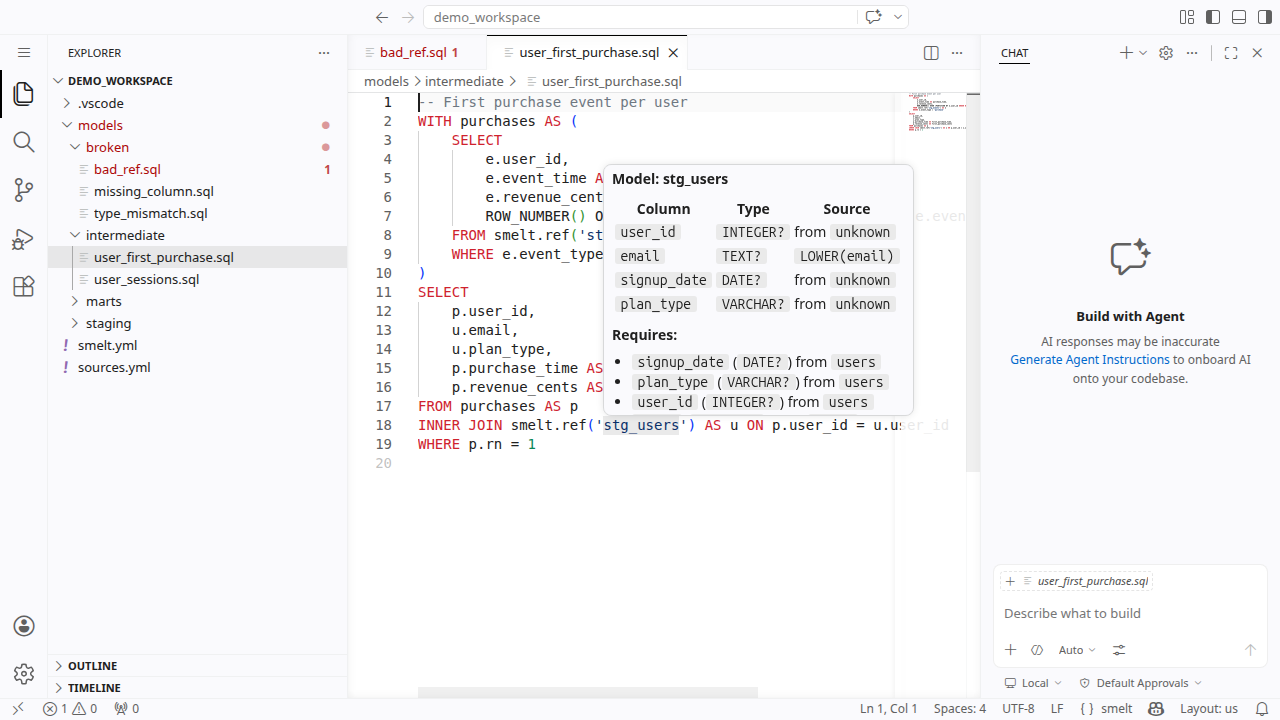
Hover Information¶
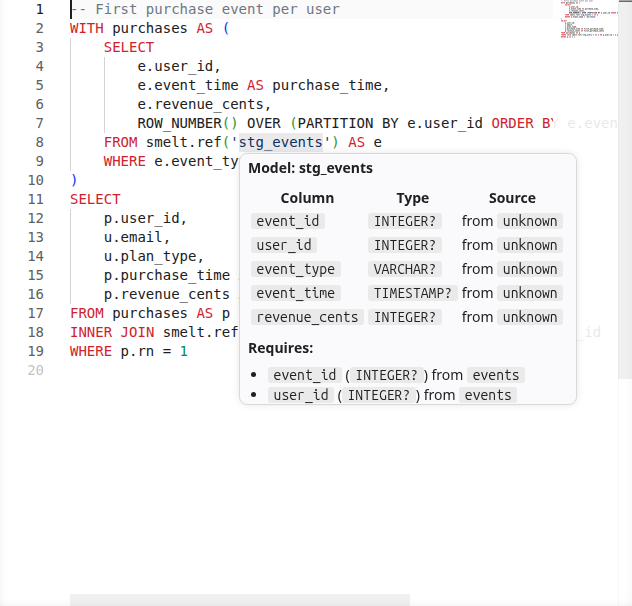
Hover over any model reference, source, or CTE to see its full schema -- column names, types, and where the data comes from.
This is particularly useful when writing joins or aggregations: you can quickly check what columns are available without switching files.
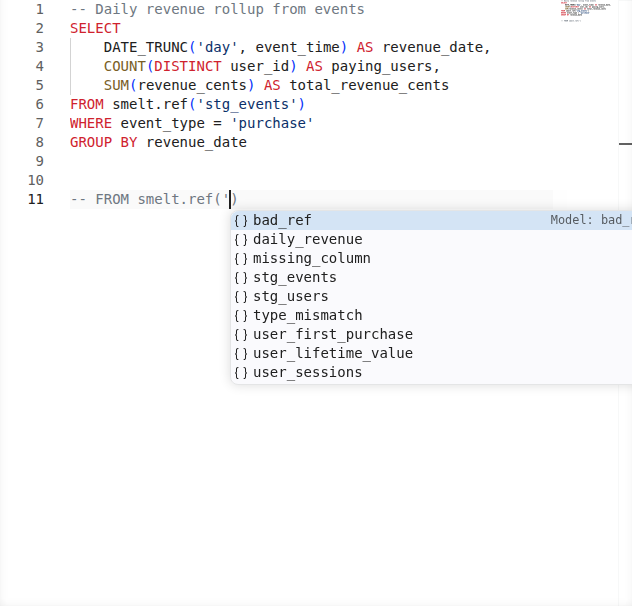
Code Completion¶
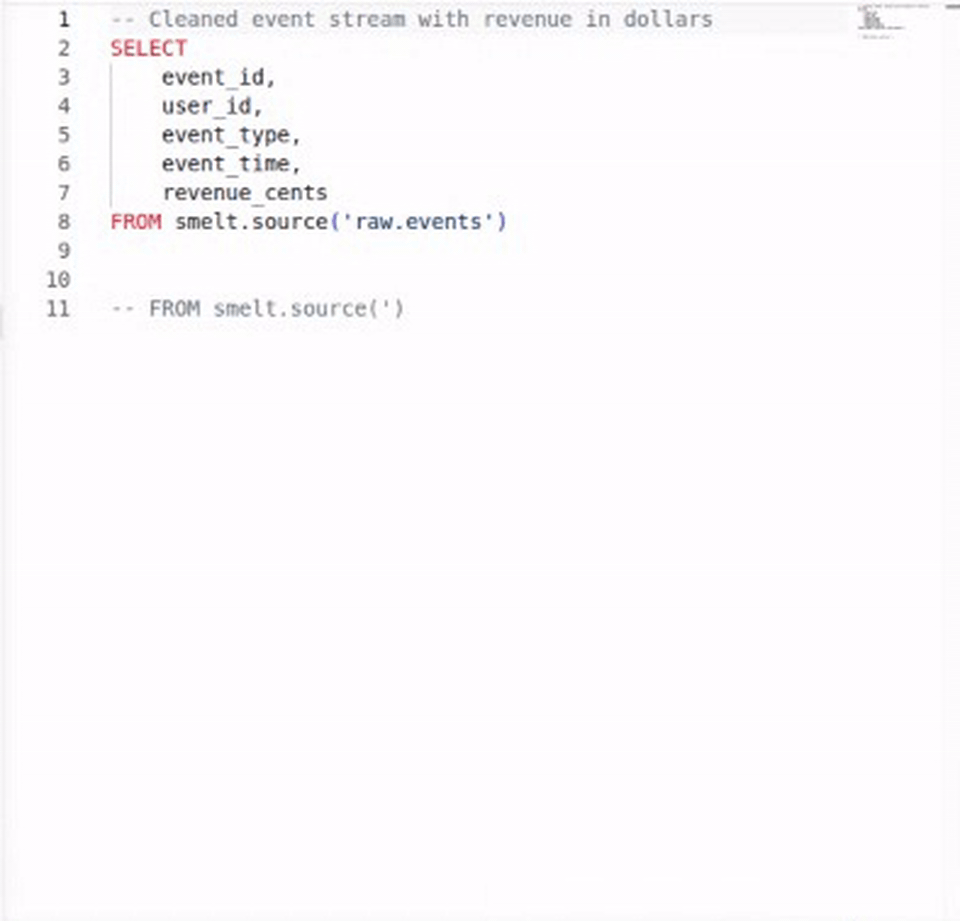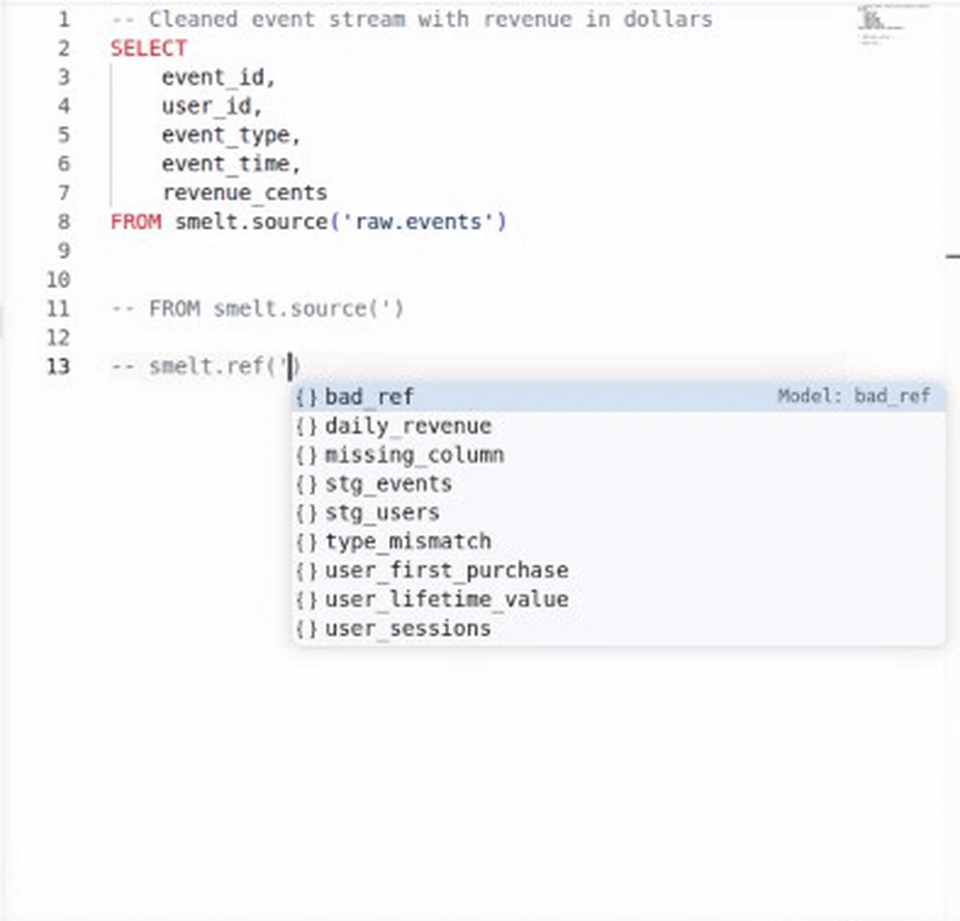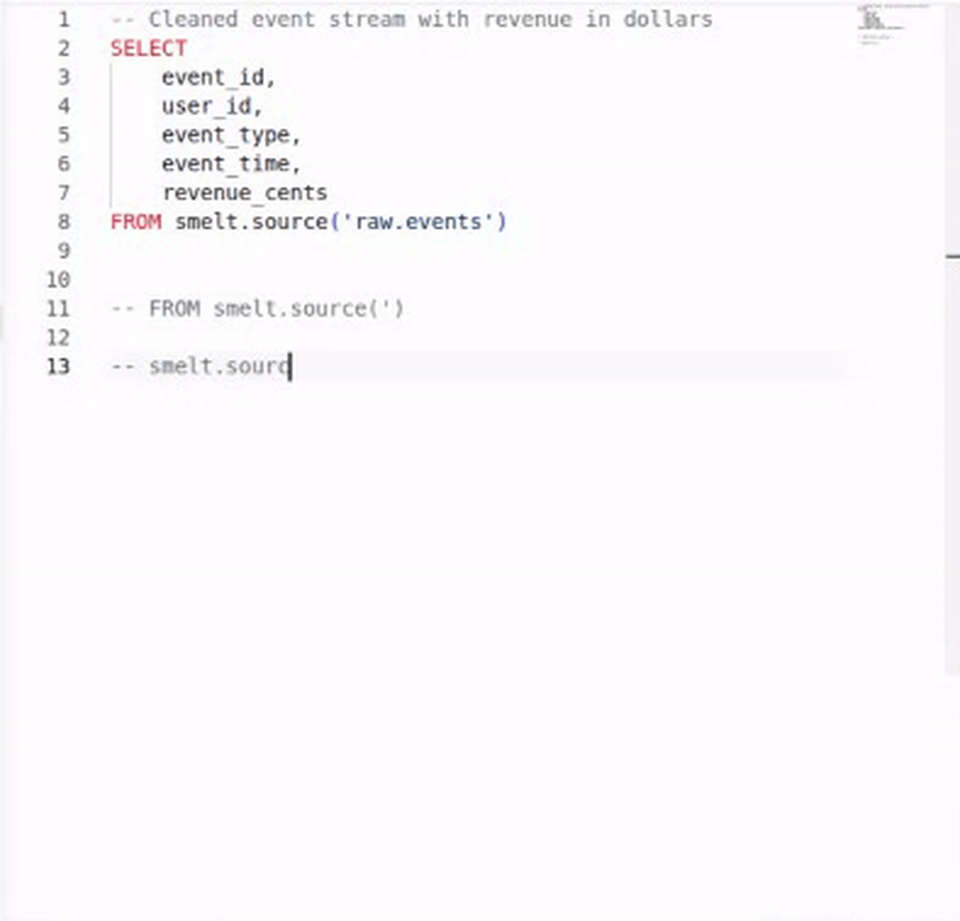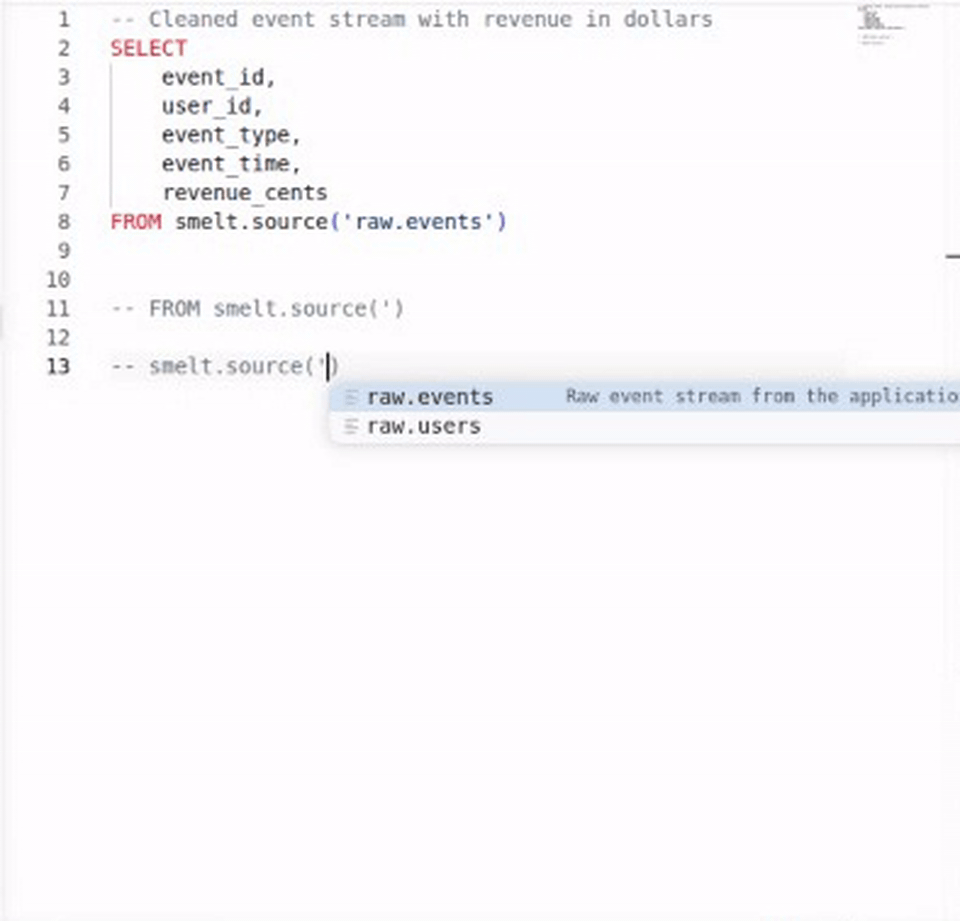
Build queries faster with context-aware completions. smelt suggests model names inside smelt.<name>, source names inside smelt.sources.<name>, and column names when you're writing SELECT lists or WHERE clauses.
Completions are schema-aware: they know what columns each upstream model exposes, so you get accurate suggestions as you type.
Find References¶
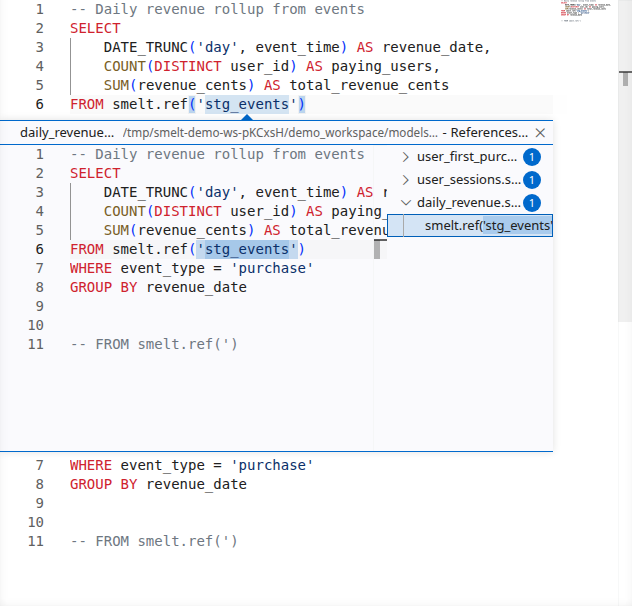
Answer "who uses this model?" with a single keystroke. Find References shows every downstream consumer of a model or every usage of a CTE within a file.
In dbt, discovering downstream impact means grepping the codebase for ref('model_name'). In smelt, it's built into the editor.
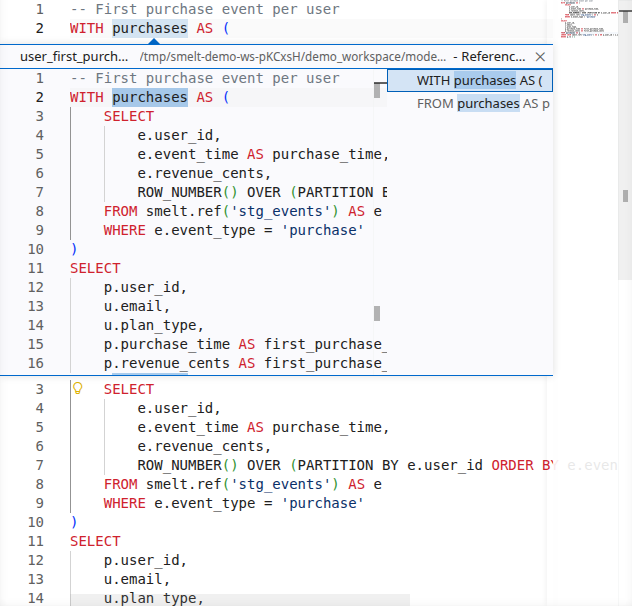
Rename Refactoring¶
Rename a model and have every reference across the project update automatically. The LSP shows a preview of all changes before applying them, so you can review the impact.
Rename refactoring works for the following targets:
| Cursor position | What is renamed |
|---|---|
smelt.<name> model reference |
All references to that model across the workspace |
| CTE name | The CTE definition and all usages within the same file |
| Column name | The column across local, upstream, and downstream files |
| Lambda parameter | The binder and every reference to it inside the lambda body |
When renaming a lambda parameter (for example the x in fn x => x + 1), the rename updates the parameter binder and every use of that parameter within the lambda's body. Inner lambdas that shadow the parameter are left untouched. The new name must be a valid identifier, must not collide with a meta-namespace keyword (if, then, else, fn, let), and must not shadow an outer binder already referenced inside the lambda body.

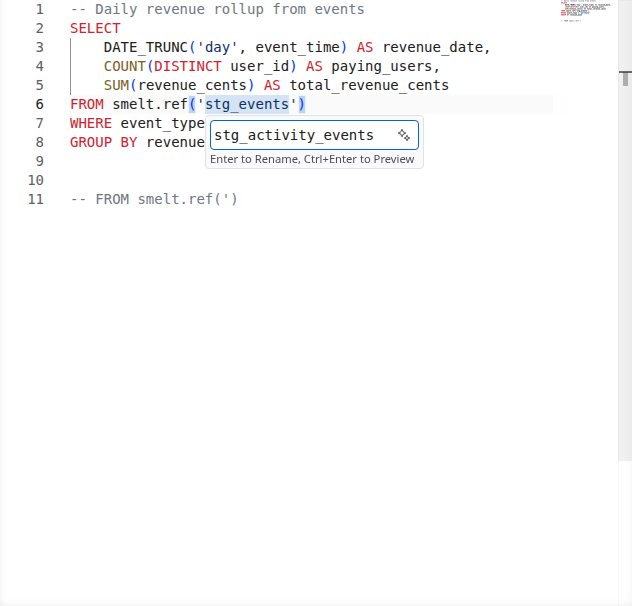
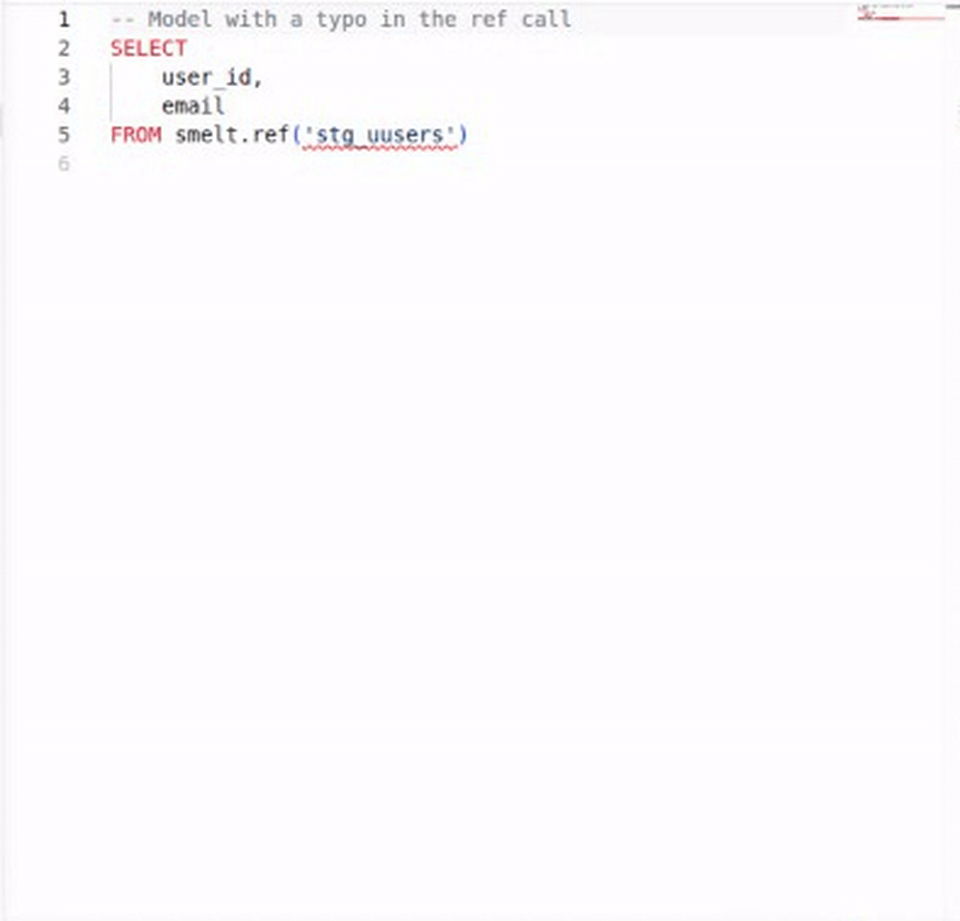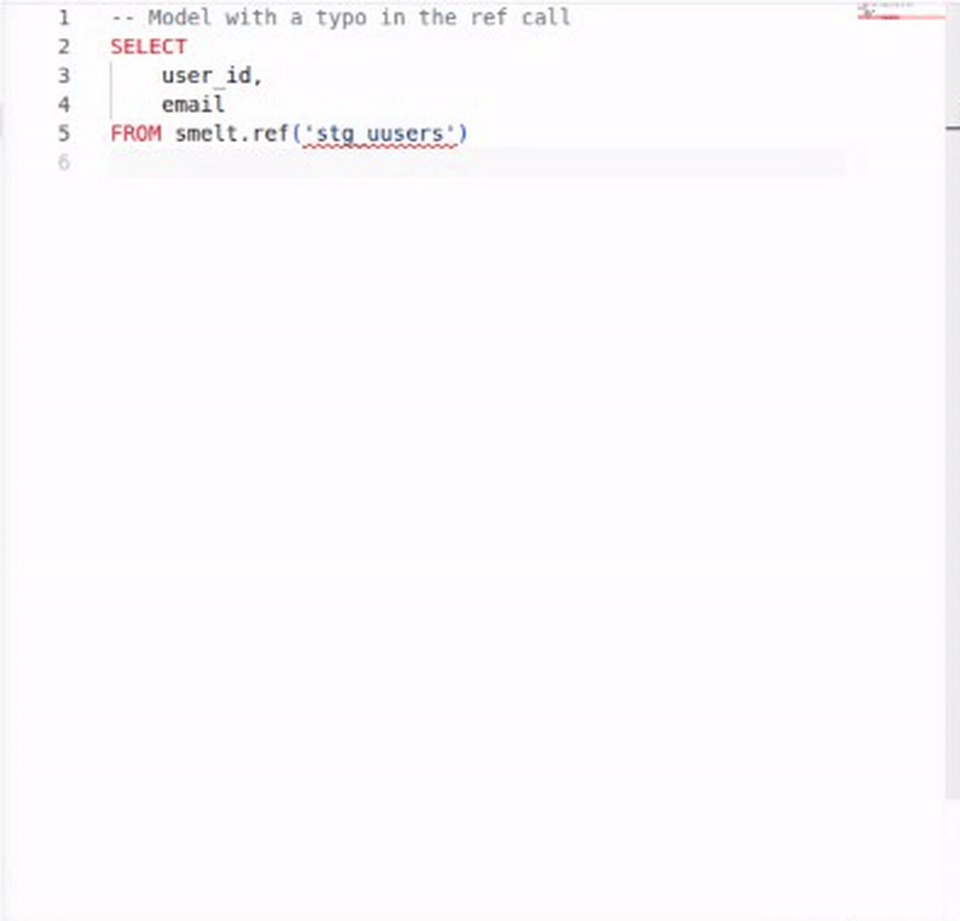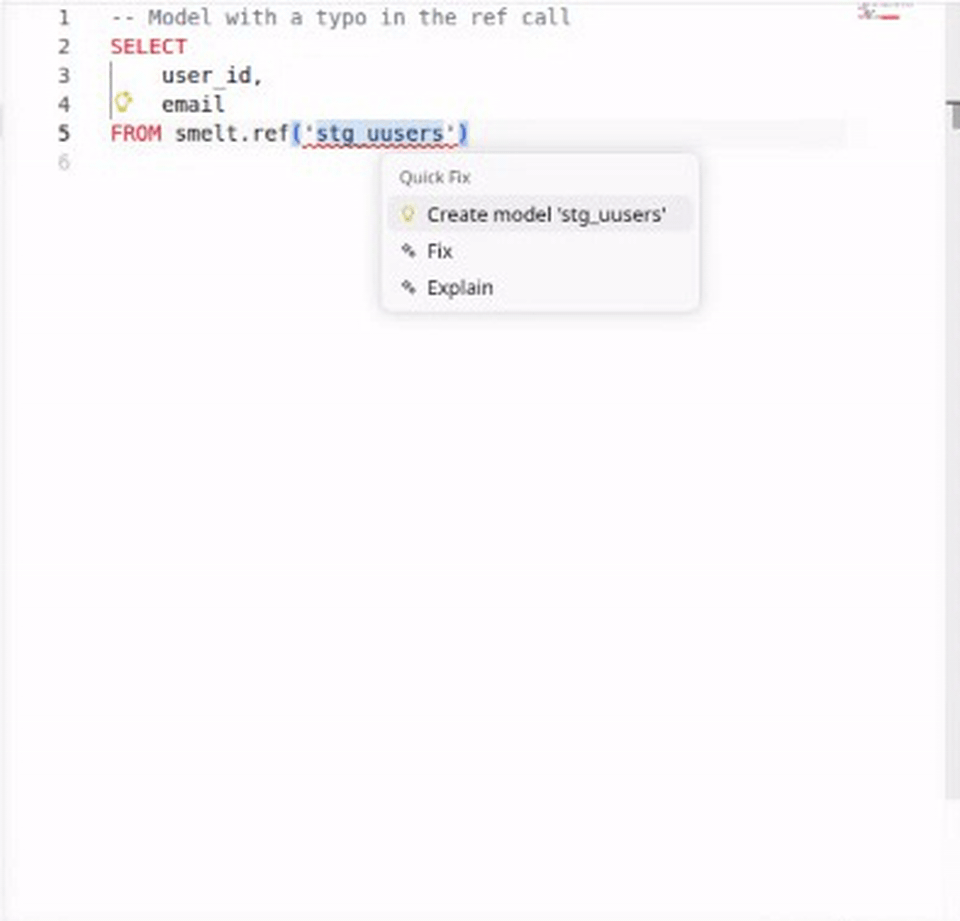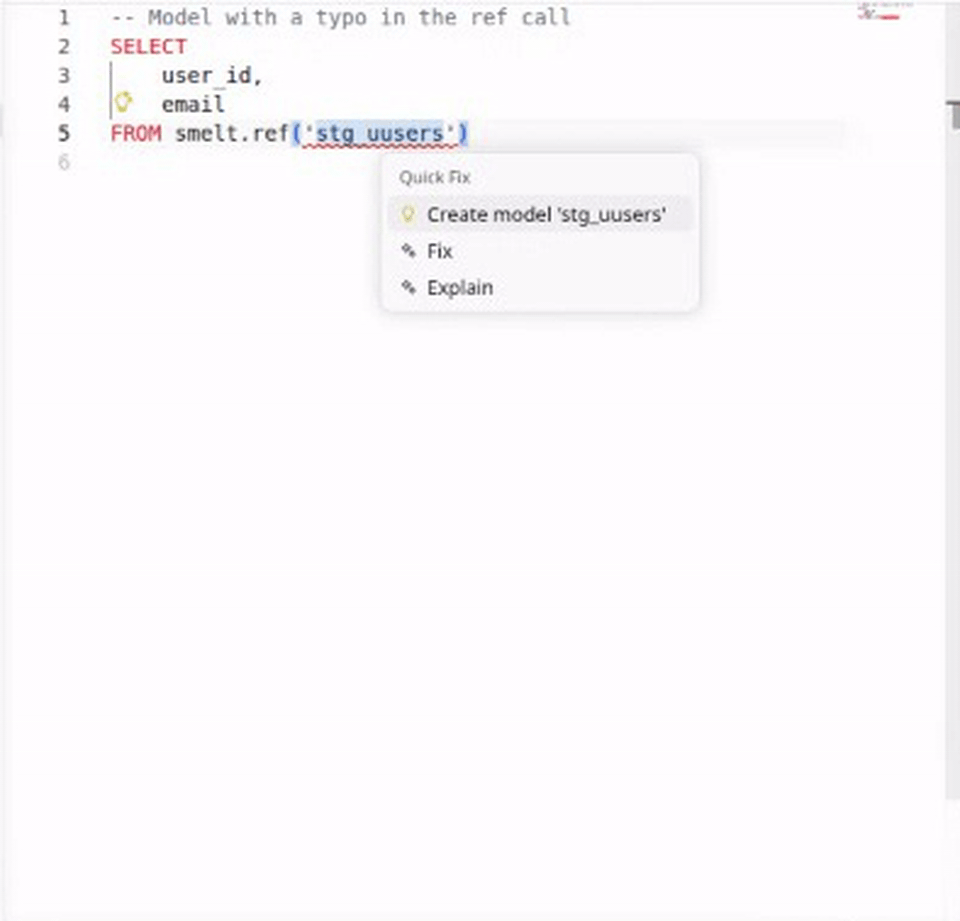
Code Actions & Quick Fixes¶
When smelt detects an error, it often suggests a fix. The most useful code action: if you reference a model that doesn't exist yet, smelt offers to create the SQL file for you.